Turn a Pandas DataFrame into an API
This post first appeared last week on dev.to.
Pandas DataFrames are my favorite way to manipulate data in Python. In fact, the end product of many of my small analytics projects is just a data frame containing my results.
I used to dump my dataframes to CSV files and save them to Github. But recently, I’ve been using Beneath, a data sharing service I’m building, to save my dataframes and simultaneously turn them into a full-blown API with a website. It’s great when I need to hand-off a dataset to clients or integrate the data into a frontend.
In this post, I’ll show you how that works! I’m going to fetch GitHub commits, analyze them, and use Beneath to turn the result into an API.
Setup Beneath
To get started, you need to install the Beneath pip module and login with a free Beneath account. It’s pretty easy and the docs already cover it. Just follow these steps.
Make sure to remember your username as you’ll need it in a minute!
Let’s analyze some data
I think Github activity is a fascinating, underexplored data source. Let’s scratch the surface and look at commits to… Pandas! Here’s a quick script to fetch the pandas source code and aggregate some daily stats on the number of commits and contributors:
import io
import pandas as pd
import subprocess
# Get all Pandas commit timestamps
repo = "pandas-dev/pandas"
cmd = f"""
if [ -d "repo" ]; then rm -Rf "repo"; fi;
git clone https://github.com/{repo}.git repo;
cd repo;
echo "timestamp,contributor";
git log --pretty=format:"%ad,%ae" --date=iso
"""
res = subprocess.run(cmd, capture_output=True, shell=True).stdout.decode()
# Group by day and count number of commits and contributors
df = (
pd.read_csv(
io.StringIO(res),
parse_dates=["timestamp"],
date_parser=lambda col: pd.to_datetime(col, utc=True),
)
.resample(rule="d", on="timestamp")["contributor"]
.agg(commits="count", contributors="nunique")
.rename_axis("day")
.reset_index()
)
Now, the df variable contains our insights. If you’re following along, you can change the repo variable to scrape another Github project. Just beware that some major repos can take a long time to analyze (I’m looking at you, torvalds/linux).
Save the DataFrame to Beneath
First, we’ll create a new project to store our results. I’ll do that from the command-line, but you can also use the web console:
beneath project create USERNAME/github-fun
Just replace USERNAME with your own username.
Now, we’re ready to publish the dataframe. We do it with a simple one-liner directly in Python (well, I split it over multiple lines, but it’s still just one call):
import beneath
await beneath.write_full(
table_path="USERNAME/github-fun/pandas-commits",
records=df,
key=["day"],
description="Daily commits to https://github.com/pandas-dev/pandas",
)
There are a few things going on here. Let’s go through them:
- The
table_pathgives the full path for the output table, including our username and project. - We use the
recordsparameter to pass our DataFrame. - We provide a
keyfor the data. The auto-generated API uses the key to index the data so we can quickly filter records. By default, Beneath will use our DataFrame’s index as the key, but I prefer setting it manually. - The
descriptionparameter adds some documentation to the dataset that will be shown at the top of the table’s page.
And that’s it! Now let’s explore the results.
Explore your data
You can now head over to the web console and browse the data and its API docs. Mine’s at https://beneath.dev/epg/github-fun/table:pandas-commits (if you used the same project and table names, you can just replace my username epg for your own).
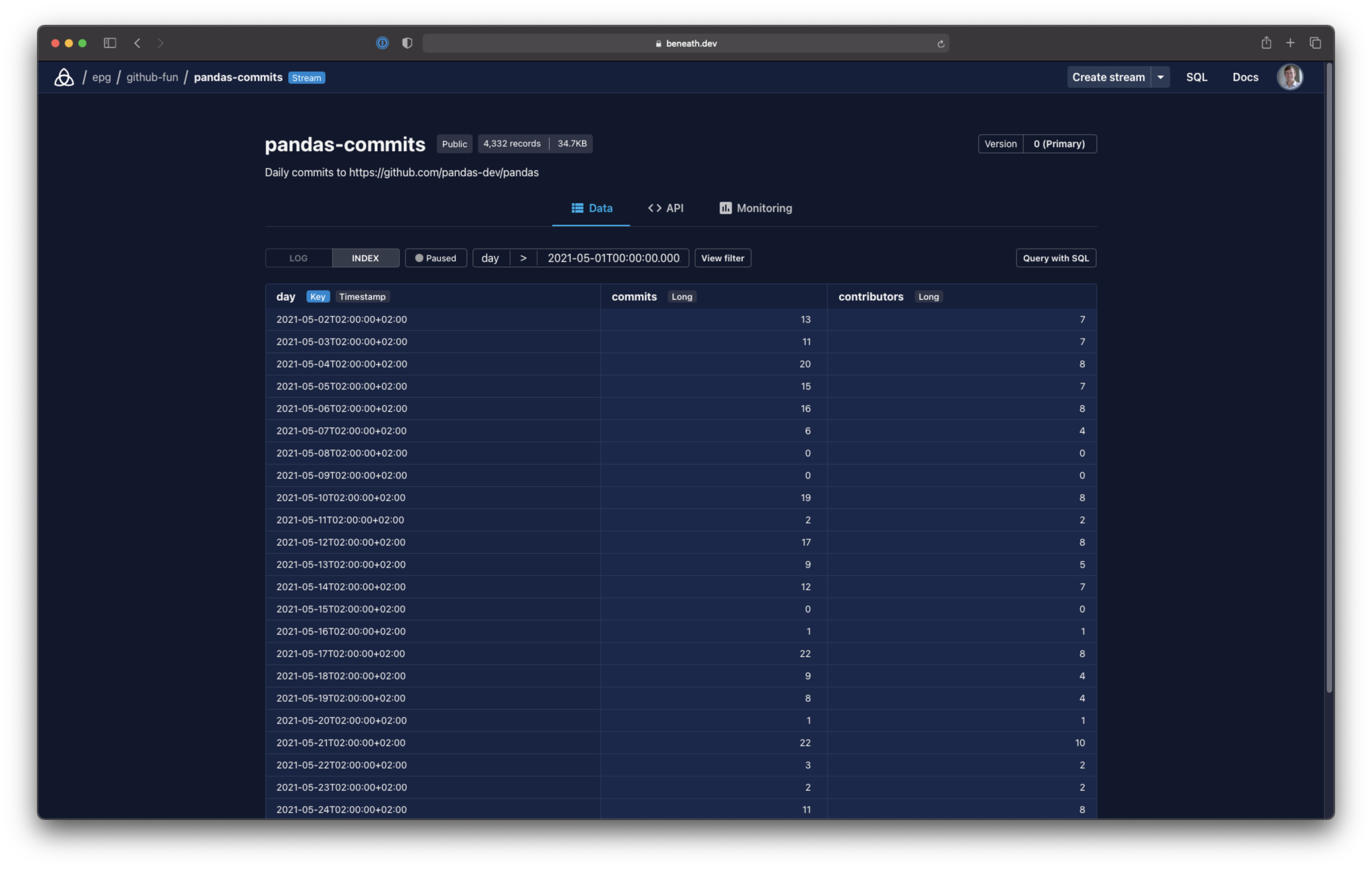
You can also share or publish the data. Permissions are managed at the project layer, so just head over to the project page and add members or flip the project settings to public.
Use the API
Now that the data is in Beneath, anyone with access can use the API. On the “API” tab of the table page, we get auto-generated code snippets for integrating the dataset.
For example, we can load the dataframe back into Python:
import beneath
df = await beneath.load_full("USERNAME/github-fun/pandas-commits")
Or we can query the REST API and get the commit info every day in May 2021:
curl https://data.beneath.dev/v1/USERNAME/github-fun/pandas-commits \
-d type=index \
-d filter='{"day":{"_gte":"2021-05-01","_lt":"2021-06-01"}}' \
-G
Or use the React hook to read data directly into the frontend:
import { useRecords } from "beneath-react";
const App = () => {
const { records, loading, error } = useRecords({
table: "USERNAME/github-fun/pandas-commits",
query: {
type: "index",
filter: '{"day":{"_gte":"2021-05-01","_lt":"2021-06-01"}}'
}
})
...
}
Check out the API tab of my dataframe in the Beneath console to see all the ways to use the data.
That’s it
That’s it! We used Beneath to turn a Pandas DataFrame into an API. If you have any questions, I’m online most of the time in Beneath’s Discord (I love to chat about data science, so you’re also welcome to just say hi 👋). And let me know if you publish a cool dataset that I can spotlight in the featured projects!